신경망
07 Apr 2019 |신경망
딥러닝의 목표는 인간과 같은 활동을 하는 것을 만드는 것이다. 그래서 나온 방법이 인간의 뇌를 프로그래밍 해보자는 것. 인간의 뇌는 아래 그림과 같이 생겼다.
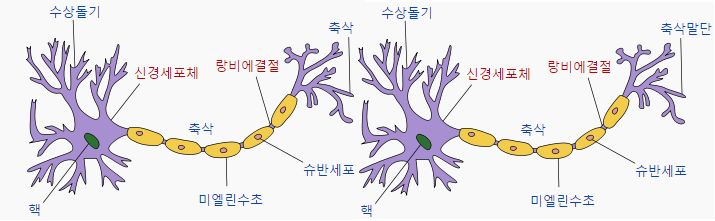
뉴런들은 이와 같이 연결 되어있는데 수상 돌기(input)에서 신호를 받아들이고 축색 돌기(output)에서 신호를 전송을 한다. 그 사이는 시냅스로 연결되어있는데 신호가 전달되기 위해서는 일정 기준(임계값 : threshold) 이상의 전기 신호가 존재해야 한다.
즉, 이 신호들의 전달을 통해서 정보를 전송하고 저장한다는 것! 이를 시스템 모델링을 하면
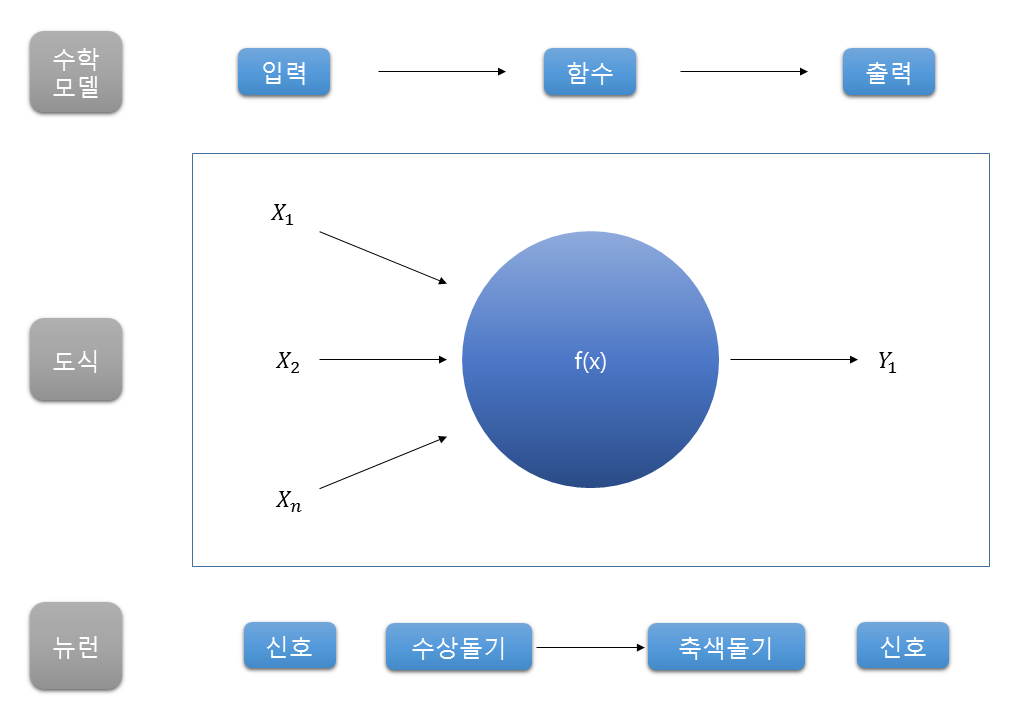
이렇게 되는데 인간은 이러한 뉴런들이 1천억개 이상, 연결은 100조개 이상이 되어있다고 한다.
1천억개의 뉴런을 간소화한 인공 신경망 구조는 아래와 같다.
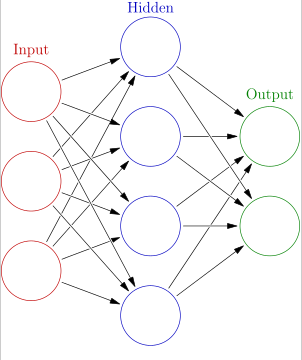
이 모델의 학습은 각 노드를 연결하는 가중치를 알아내는 것이다. 뉴런을 연결하는 시냅스의 threshold를 찾는 것처럼.
여기서 Input을 입력층, Hidden을 은닉층, Output을 출력층으로 표현을 한다. 신경망은 알아서 가중치 값을 설정하고 input, output의 예상 값을 실제 값과 비교하면서 조정해 나가면서 학습해 나간다. 이 오차를 활성화 함수와 손실함수, 경사하강법 등을 이용해 계속 줄여나가는 것이 학습이다.
신경망에는 층이 있는데 input을 제외한 hidden layer와 output layer의 층의 갯수를 통해 n층 신경망이라고 부른다. 학습이 가장 잘되는 layer와 node 갯수는 아직 발견되지 못했다. 위의 그림은 2층 신경망이다. 그러면 2층 신경망과 3층 신경망의 구현에 대해 알아보겠다.
2층 신경망 구현
from scratch.common.functions import *
from scratch.common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis = 1)
t = np.argmax(t, axis = 1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
3층 신경망 구현
import numpy as np
def sigmoid(x):
return 1/ (1+np.exp(-x))
def relu(x):
return np.maximum(0.5,x)
def init_network():
network = {}
network['w1'] = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]])
network['b1'] = np.array([0.1,0.2,0.3])
network['w2'] = np.array([[0.1,0.4],[0.2,0.5],[0.3,0.6]])
network['b2'] = np.array([0.1,0.2])
network['w3'] = np.array([[0.1,0.3],[0.2,0.4]])
network['b3'] = np.array([0.1,0.2])
return network
def forward(network, x):
W1, W2, W3 = network['w1'], network['w2'], network['w3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x,W1)+b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2)+b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3)+b3
y = relu(a3)
return y
network = init_network()
x = np.array([1.0,0.5])
y = forward(network,x)